
SEO Robots Attack.
Feeling Like the Last Man Standing: Navigating the Surge in Web Scraping and Skyrocketing CDN Costs.
“Every morning was like a last fight. I feel like the last man standing.” This is the reality many website owners and operators are facing today. We’re grappling with a significant, often mysterious, surge in traffic, desperately trying to identify why our CDN usage bills have doubled, or even tripled.
Recently, it’s become increasingly common for website owners to notice a dramatic increase in traffic that doesn’t correlate with legitimate user activity. Whether you’re using Fastly, Akamai, or any other CDN solution, you’ve likely seen the impact on your operational costs.
The reason? The AI boom.
As companies race to keep pace in the AI arms race, the demand for vast datasets to train thousands of large language models (LLMs) has exploded. This insatiable hunger for data means that virtually every accessible website on the planet is under active, often aggressive, scanning and scraping. These aren’t always the well-behaved bots we’re used to; many are unauthorized, resource-intensive, and fly under the radar of traditional bot management.
So, what can we do to protect our digital assets and control these spiraling costs?
We need a multi-layered approach to differentiate between beneficial bots and the unwelcome guests.
Handling Known and Positive Bots:
For reputable bots like those from Google, Amazon, Bing, and even ChatGPT, the solution is relatively straightforward. Leveraging the robots.txt file is an effective way to provide instructions and manage their crawling behavior. These bots generally respect these directives, allowing you to control access for legitimate indexing and data collection.
User-agent: GPTBotDisallow: /*?brand=*Disallow: /*?category=*Disallow: /*?filter_id=Disallow: /*?p=*Addressing the Unknown and Malicious Scrapers:
The real challenge lies with the “some unknown guys” – the unauthorized scrapers and malicious bots that ignore robots.txt and consume valuable resources. Combating these requires more active measures:
- Block by IP: Identifying and blocking specific IP addresses known to be sources of malicious activity is a fundamental step. However, attackers often use rotating IPs, making this a constant battle.
- Block by Geo-location: If you’re seeing significant malicious traffic from specific geographic regions where your target audience is not located, blocking by geo-location can be an effective filter.
- Block by User Agent: Analyzing and blocking suspicious or clearly non-browser user agents can help filter out automated scripts attempting to mimic legitimate users. Fasly can do it by using VCL rules:
if (req.http.User-Agent ~ "Java" || req.http.User-Agent ~ "Gigabot" || req.http.User-Agent ~ "NjuiceBot" … req.http.User-Agent ~ "Mb2345Browser") { error 405 "Not allowed"; }- Block by WAF and Rate Limits: Implementing a robust Web Application Firewall (WAF) is crucial. WAFs can detect and block malicious patterns and known bot signatures. Complementing this with rate limiting – restricting the number of requests from a single source within a given time frame – can significantly mitigate the impact of high-volume scraping attempts.
Address Adobe Commerce and Fastly:
The following rules can help protect your Adobe Commerce website against unexpected scanning.
1. Update Robots.txt with more detail instructions for knowns search bots: Google, GoogleOthers, Bing, Amazon, GPT.
Gemini and GPT are functioning optimally with the instructions in the robots.txt file, allowing us to limit the amount of data indexed by recognized LLM models.

2. Utilize a custom Fastly VCL to block unreliable bots.
To block abusive crawling at the Fastly level, collect abusive crawler user agents using a NewRelic tool or command-line utility and create a custom VCL rule.

3. Fix 404 for favicon and Apple images.
Since 404 content is generating high volume traffic, it is better to either serve a zero-size pixel for such requests or deny the traffic entirely.

4. Enable Fastly Rate Limits for Abusive Crowlers.
Fastly provides primitives that can be used to apply rate limiting to your service. This is designed to help you control the rate of requests sent to your Fastly services and origin servers from individual clients or clients forming a single identifiable group. Rate limit helps to prevent abusive use of a website by blocking abusive traffic.
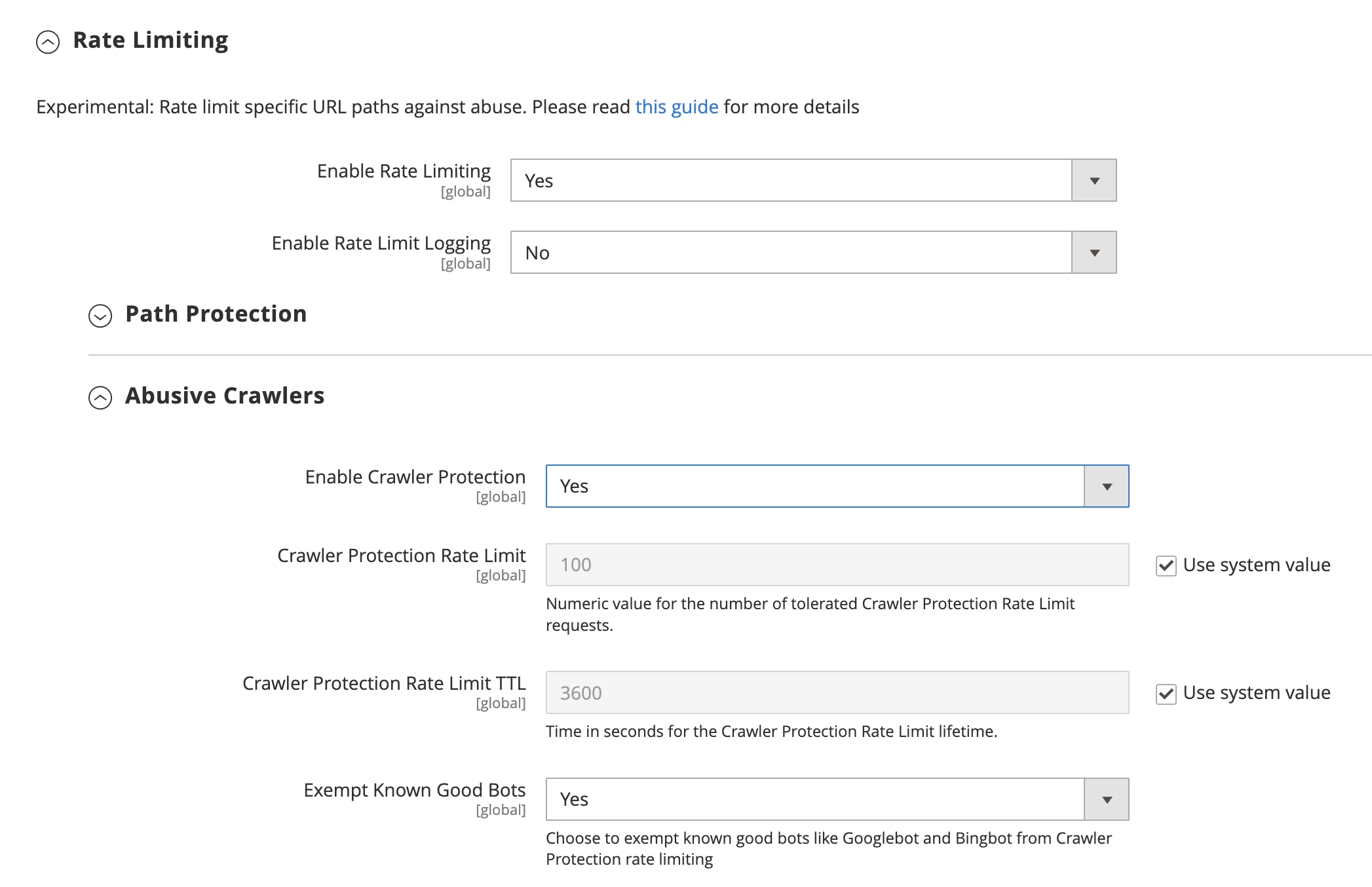
5. Block / Allow traffic from the specific countries only.

Combating massive bot attacks and unauthorized web scraping is an ongoing challenge in the age of AI. It requires constant vigilance, analysis, and the implementation of layered security measures. By understanding the drivers behind this surge and employing the right strategies, we can better protect our websites, control costs, and stop feeling like the last man standing in this digital fight.
